Persistent Workers
This page covers how to use persistent workers, the benefits, requirements, and how workers affect sandboxing.
A persistent worker is a long-running process started by the Bazel server, which
functions as a wrapper around the actual tool (typically a compiler), or is
the tool itself. In order to benefit from persistent workers, the tool must
support doing a sequence of compilations, and the wrapper needs to translate
between the tool’s API and the request/response format described below. The same
worker might be called with and without the --persistent_worker flag
in the same build, and is responsible for appropriately starting and talking to
the tool, as well as shutting down workers on exit. Each worker instance is
assigned (but not chrooted to) a separate working directory under
<outputBase>/bazel-workers.
Using persistent workers is an execution strategy that decreases start-up overhead, allows more JIT compilation, and enables caching of for example the abstract syntax trees in the action execution. This strategy achieves these improvements by sending multiple requests to a long-running process.
Persistent workers are implemented for multiple languages, including Java, Scala, Kotlin, and more.
Programs using a NodeJS runtime can use the @bazel/worker helper library to implement the worker protocol.
Using persistent workers
Bazel 0.27 and higher
uses persistent workers by default when executing builds, though remote
execution takes precedence. For actions that do not support persistent workers,
Bazel falls back to starting a tool instance for each action. You can explicitly
set your build to use persistent workers by setting the worker
strategy for the applicable tool mnemonics.
As a best practice, this example includes specifying local as a fallback to
the worker strategy:
bazel build //my:target --strategy=Javac=worker,local
Using the workers strategy instead of the local strategy can boost compilation speed significantly, depending on implementation. For Java, builds can be 2–4 times faster, sometimes more for incremental compilation. Compiling Bazel is about 2.5 times as fast with workers. For more details, see the “Choosing number of workers” section.
If you also have a remote build environment that matches your local build
environment, you can use the experimental
dynamic strategy,
which races a remote execution and a worker execution. To enable the dynamic
strategy, pass the
–experimental_spawn_scheduler
flag. This strategy automatically enables workers, so there is no need to
specify the worker strategy, but you can still use local or sandboxed as
fallbacks.
Choosing number of workers
The default number of worker instances per mnemonic is 4, but can be adjusted
with the
worker_max_instances
flag. There is a trade-off between making good use of the available CPUs and the
amount of JIT compilation and cache hits you get. With more workers, more
targets will pay start-up costs of running non-JITted code and hitting cold
caches. If you have a small number of targets to build, a single worker may give
the best trade-off between compilation speed and resource usage (for example,
see issue #8586. The
worker_max_instances flag sets the maximum number of worker instances per
mnemonic and flag set (see below), so in a mixed system you could end up using
quite a lot of memory if you keep the default value. For incremental builds the
benefit of multiple worker instances is even smaller.
This graph shows the from-scratch compilation times for Bazel (target
//src:bazel) on a 6-core hyper-threaded Intel Xeon 3.5 GHz Linux workstation
with 64 GB of RAM. For each worker configuration, five clean builds are run and
the average of the last four are taken.
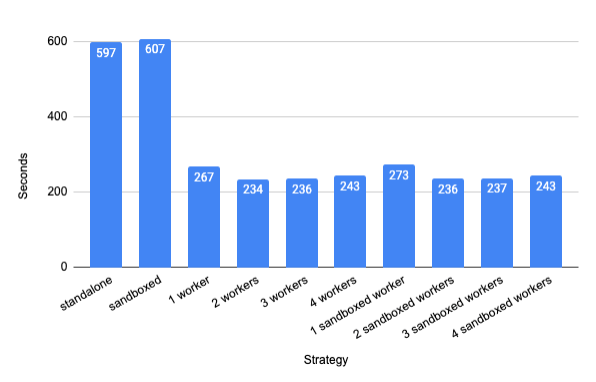
For this configuration, two workers give the fastest compile, though at only 14% improvement compared to one worker. One worker is a good option if you want to use less memory.
Incremental compilation typically benefits even more. Clean builds are
relatively rare, but changing a single file between compiles is common, in
particular in test-driven development. The above example also has some non-Java
packaging actions to it that can overshadow the incremental compile time.
Recompiling the Java sources only
(//src/main/java/com/google/devtools/build/lib/bazel:BazelServer_deploy.jar)
after changing an internal string constant in
AbstractContainerizingSandboxedSpawn.java
gives a 3x speed-up (average of 20 incremental builds with one warmup build
discarded):
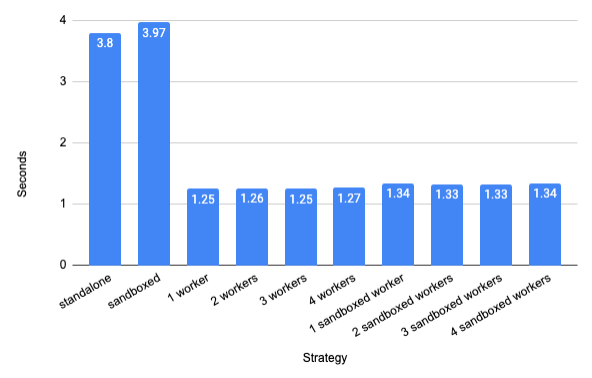
The speed-up depends on the change being made. A speed-up of a factor 6 is measured in the above situation when a commonly used constant is changed.
Modifying persistent workers
You can pass the
--worker_extra_flag
flag to specify start-up flags to workers, keyed by mnemonic. For instance,
passing --worker_extra_flag=javac=--debug turns on debugging for Javac only.
Only one worker flag can be set per use of this flag, and only for one mnemonic.
Workers are not just created separately for each mnemonic, but also for
variations in their start-up flags. Each combination of mnemonic and start-up
flags is combined into a WorkerKey, and for each WorkerKey up to
worker_max_instances workers may be created. See the next section for how the
action configuration can also specify set-up flags.
You can use the
--high_priority_workers
flag to specify a mnemonic that should be run in preference to normal-priority
mnemonics. This can help prioritize actions that are always in the critical
path. If there are two or more high priority workers executing requests, all
other workers are prevented from running. This flag can be used multiple times.
Passing the
--worker_sandboxing
flag makes each worker request use a separate sandbox directory for all its
inputs. Setting up the sandbox takes some extra time,
especially on macOS, but gives a better correctness guarantee.
You can use the --experimental_worker_allow_json_protocol flag to allow
workers to communicate with Bazel through JSON instead of protocol buffers
(protobuf). The worker and the rule that consumes it can then be modified to
support JSON.
The
--worker_quit_after_build
flag is mainly useful for debugging and profiling. This flag forces all workers
to quit once a build is done. You can also pass
--worker_verbose to get
more output about what the workers are doing. This flag is reflected in the
verbosity field in WorkRequest, allowing worker implementations to also be
more verbose.
Workers store their logs in the <outputBase>/bazel-workers directory, for
example
/tmp/_bazel_larsrc/191013354bebe14fdddae77f2679c3ef/bazel-workers/worker-1-Javac.log.
The file name includes the worker id and the mnemonic. Since there can be more
than one WorkerKey per mnemonic, you may see more than worker_max_instances
log files for a given mnemonic.
For Android builds, see details at the Android Build Performance page.
Implementing persistent workers
See the creating persistent workers page for information on how to make a worker.
This example shows a Starlark configuration for a worker that uses JSON:
args_file = ctx.actions.declare_file(ctx.label.name + "_args_file")
ctx.actions.write(
output = args_file,
content = "\n".join(["-g", "-source", "1.5"] + ctx.files.srcs),
)
ctx.actions.run(
mnemonic = "SomeCompiler",
executable = "bin/some_compiler_wrapper",
inputs = inputs,
outputs = outputs,
arguments = [ "-max_mem=4G", "@%s" % args_file.path],
execution_requirements = {
"supports-workers" : "1", "requires-worker-protocol" : "json" }
)
With this definition, the first use of this action would start with executing
the command line /bin/some_compiler -max_mem=4G --persistent_worker. A request
to compile Foo.java would then look like:
arguments: [ "-g", "-source", "1.5", "Foo.java" ]
inputs: [
{path: "symlinkfarm/input1" digest: "d49a..." },
{path: "symlinkfarm/input2", digest: "093d..."},
]
The worker receives this on stdin in JSON format (because
requires-worker-protocol is set to JSON, and
--experimental_worker_allow_json_protocol is passed to the build to enable
this option). The worker then performs the action, and sends a JSON-formatted
WorkResponse to Bazel on its stdout. Bazel then parses this response and
manually converts it to a WorkResponse proto. To communicate
with the associated worker using binary-encoded protobuf instead of JSON,
requires-worker-protocol would be set to proto, like this:
execution_requirements = {
"supports-workers" : "1" ,
"requires-worker-protocol" : "proto"
}
If you do not include requires-worker-protocol in the execution requirements,
Bazel will default the worker communication to use protobuf.
Bazel derives the WorkerKey from the mnemonic and the shared flags, so if this
configuration allowed changing the max_mem parameter, a separate worker would
be spawned for each value used. This can lead to excessive memory consumption if
too many variations are used.
Each worker can currently only process one request at a time. The experimental multiplex workers feature allows using multiple threads, if the underlying tool is multithreaded and the wrapper is set up to understand this.
In this GitHub repo, you can see example worker wrappers written in Java as well as in Python. If you are working in JavaScript or TypeScript, the @bazel/worker package and nodejs worker example might be helpful.
How do workers affect sandboxing?
Using the worker strategy by default does not run the action in a
sandbox, similar to the local strategy. You can set
the --worker_sandboxing flag to run all workers inside sandboxes, making sure
each execution of the tool only sees the input files it’s supposed to have. The
tool may still leak information between requests internally, for instance
through a cache. Using dynamic strategy requires workers to be sandboxed.
To allow correct use of compiler caches with workers, a digest is passed along with each input file. Thus the compiler or the wrapper can check if the input is still valid without having to read the file.
Even when using the input digests to guard against unwanted caching, sandboxed workers offer less strict sandboxing than a pure sandbox, because the tool may keep other internal state that has been affected by previous requests.
Multiplex workers can only be sandboxed if the worker implementation support it,
and this sandboxing must be separately enabled with the
--experimental_worker_multiplex_sandboxing flag. See more details in
the design doc)
Further reading
For more information on persistent workers, see: